 or Hive")
Problem
Given a (web) app, generating data, it comes a time when you want to query that data – for Analytics, reporting or debugging purposes.
Even when dealing with TBs of data representing the (web) app records, it would be extremely useful to be able to just do:
SELECT * from web_app WHERE transaction_id = 'abc';
and get a result like:
| Customer | Date | Server | Errors | Target URL | Request Headers | transaction_id |
|---|---|---|---|---|---|---|
| AwesomeCustomer1 | 2020-12-12 12:00:00 | mywebapp3 | [{1003, “Invalid payload received”}] | /upload | abc |
or
SELECT customer_name, count(*) as total_requests
FROM web_app
WHERE month = 'June' and year = '2020'
GROUP BY customer_name
ORDER BY total_requests DESC
| customer_name | total_requests |
|---|---|
| AwesomeCustomer1 | 11,330,191 |
| OtherAwesomeCustomer | 9,189,107 |
| IsAwesome | 2,900,261 |
or
SELECT customer_name, sum(cost) as total_cost
FROM web_app
WHERE month = 'June' and year = '2020'
GROUP BY customer_name
ORDER BY total_cost DESC
LIMIT 10
| customer_name | total_cost |
|---|---|
| AwesomeCustomer1 | $171,333 |
| OtherAwesomeCustomer | $150,018 |
| IsAwesome | $55,190 |
Well, it turns out that you can do exactly this! Even with TBs and even PBs of data.
A typical example might be a server app generating data which we decide to store (e.g. in Amazon S3, or Hadoop File System). Suppose our app is generating protobuf messages (for instance, one probouf message for each HTTP request). We then want to be able to run queries on top of this data.
Obviously, we might have multiple (web) app servers generating a lot of data. We might generate TBs or even PBs of data and want to be able to query it in a timely fashion.
Solution
In order to make it easy to run queries on our data, we can use tools such as Amazon Athena (based on Presto), Hive or others. These allow us to use standard SQL to query the data, which is quite nice. These tools work best (in terms of speed and usability) when our data is in a columnar storage format, such as Apache Parquet.
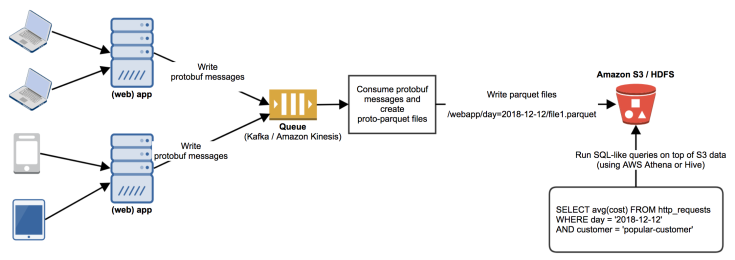
A typical example for the flow of data would be something like this:
1. (Web) app generates a (protobuf) message and writes it to a queue (such as Kafka or Amazon Kinesis). This is our data producer.
2. A consumer would read these messages from the queue, bundle them and generate a parquet file. In our case we’re dealing with protobuf messages, therefore the result will be a proto-parquet binary file. We can take this file (which might contain millions of records) and upload it to a storage (such as Amazon S3 or HDFS).
3. Once the parquet data is in Amazon S3 or HDFS, we can query it using Amazon Athena or Hive.
So let’s dive and see how we can implement each step.
1. Generate protobuf messages and write them to a queue
Let’s take the following protobuf schema.
message HttpRequest {
string referrer_url = 1;
string target_url = 2; // Example: /products
string method = 3; // GET, POST, PUT, DELETE etc.
map request_headers = 4;
map request_params = 5; // category=smartphones
bool is_https = 6;
string user_agent = 7;
int32 response_http_code = 8;
map response_headers = 9;
string transaction_id = 10;
string server_hostname = 11;
}
Protobuf (developed by Google) supports a number of programming languages such as: Java, C++, python, Objective-C, C# etc.
Once we have the protobuf schema, we can compile it. We’ll use Java in our example.
We now have created the protobuf messages. Each message contains information information about a single HTTP request. You can think of it as a record in an database table.
In order to query billions of records in a matter of seconds, without anything catching fire, we can store our data in a columnar format (see video). Parquet provides this.
2. Generate Parquet files
Once we have the protobuf messages, we can batch them together and convert them to parquet. Parquet offers the tool to do this.
public class ParquetGenerator {
public static void main(String[] args) throws IOException {
List messages = fetchMessagesFromQueue(1000);
log.info("Writing {} messages to the parquet file.", messages.size());
Path outputPath = new Path("/tmp/file1.parquet");
writeToParquetFile(outputPath, messages);
}
/**
* Converts Protobuf messages to Proto-Parquet and writes them in the specified path.
*/
public static void writeToParquetFile(Path file,
Collection messages) throws IOException {
Configuration conf = new Configuration();
ProtoWriteSupport.setWriteSpecsCompliant(conf, true);
try (ParquetWriter writer = new ParquetWriter(
file,
new ProtoWriteSupport(HttpRequest.class),
GZIP,
PARQUET_BLOCK_SIZE,
PARQUET_PAGE_SIZE,
PARQUET_PAGE_SIZE, true,
false,
DEFAULT_WRITER_VERSION,
conf)) {
for (HttpRequest record : messages) {
writer.write(record);
}
}
}
}
Note: We are using protobuf 1.10.1-SNAPSHOT which has added Hive/Presto (AWS Athena) support in ProtoParquet
3. Upload the data in Amazon S3
In the previous step we just wrote the file on the local disk. We can now upload it to Amazon S3 or Hive. We’ll use S3 in our example.
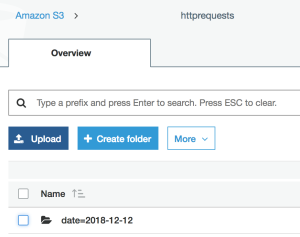
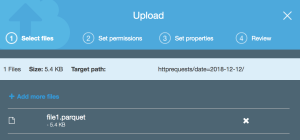
4. Query the parquet data
Once the data is stored in S3, we can query it. We’ll use Amazon Athena for this. Note that Athena will query the data directly from S3. No need to transform the data anymore to load it into Athena. We just need to point the S3 path to Athena and the schema.
a. Let’s create the Athena schema
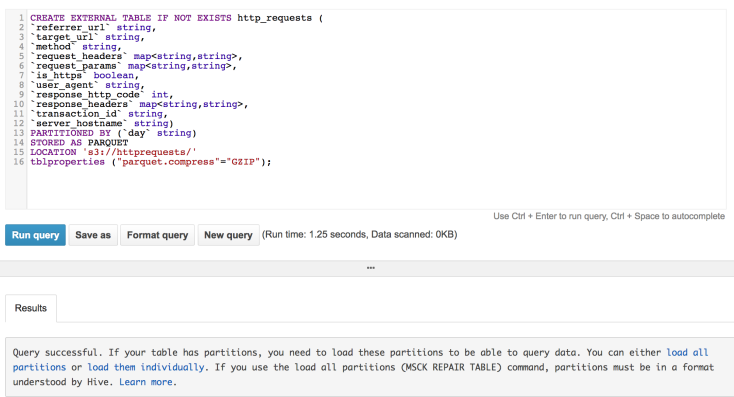
CREATE EXTERNAL TABLE IF NOT EXISTS http_requests (
`referrer_url` string,
`target_url` string,
`method` string,
`request_headers` map,
`request_params` map,
`is_https` boolean,
`user_agent` string,
`response_http_code` int,
`response_headers` map,
`transaction_id` string,
`server_hostname` string)
PARTITIONED BY (`date` string)
STORED AS PARQUET
LOCATION 's3://httprequests/'
tblproperties ("parquet.compress"="GZIP");
b. Let’s load the partitions
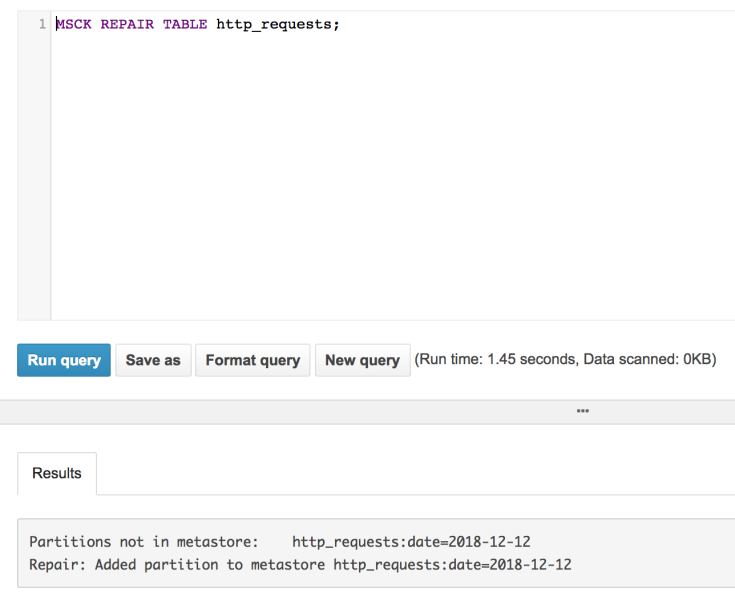
MSCK REPAIR TABLE http_requests;
Note: You can use AWS Glue to automatically determine the schema (from the parquet files) and to automatically load new partitions.
c. Let’s do a test query
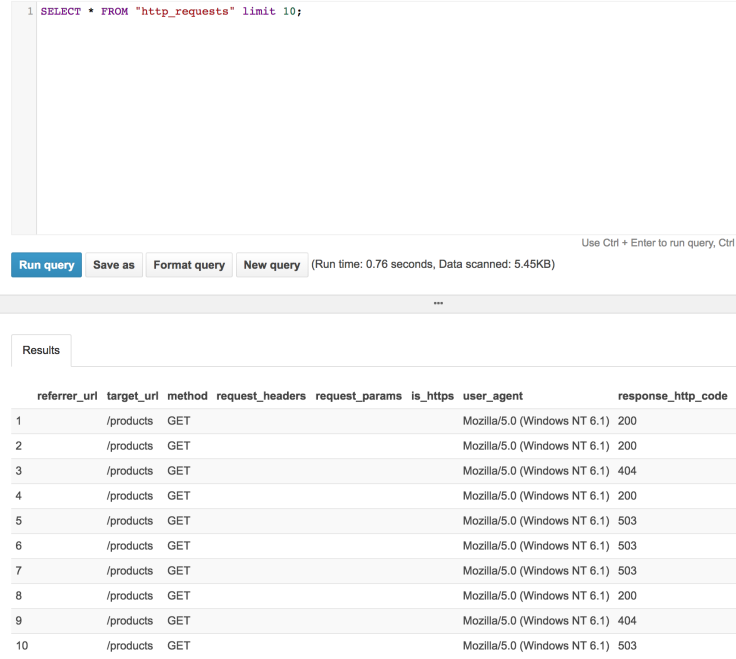

Would this work if your protocol buffer schema had a repeated complex type? How would Athena handle it?
LikeLike
Good question @Andrew Schein. Yes, this also works with repeated types (arrays). It can either be a list of primitives (ints, strings) or a list of messages (list of structs). Presto (AWS Athena) has a series of functions that work on lists: http://teradata.github.io/presto/docs/127t/functions/array.html
LikeLike